Streaming data is a problem domain I've played with a lot in
Haskell. In Haskell, the closest we come to built-in streaming data
support is laziness-by-default, which doesn't fully capture
streaming data. (I'm not going into those details today, but if you
want to understand this better, there's plenty of information in
the conduit
tutorial.) Real streaming data is handled at the library level
in Haskell, with many different options available.
Rust does things differently: it bakes in a concept called
iterators not only with the standard library, but the language
itself: for loops are built-in syntax for iterators.
There are some interesting trade-offs to discuss regarding solving
a problem in the language itself versus a library, which I'm not
going to get into.
Also, Rust's approach follows a state machine design, as opposed
to many Haskell libraries which use coroutines. That choice turns
out to be pretty crucial to getting good performance, and applies
in the Haskell world as well. In fact, I've already
blogged about this concept with my aptly-named Vegito concept.
For those familiar with it: you'll see some crossovers in this blog
post, but prior knowledge isn't necessary.
While digging into the implementation of iterators in Rust, I
found it very enlightening how the design differed from what
idiomatic Haskell would look like. Trying to mirror the design from
one language in the other really demonstrates some profound
differences in the languages, which is what I'm going to try and
dive in on today.
To motivate the examples here, we're going to try to perform the
same computation many times: stream the numbers from 1 to
1,000,000, filter to just the evens, multiply every number by 2,
and then sum them up. You can find
all of the code in a Gist. Here's an overview of the benchmark
results, with many more details below:
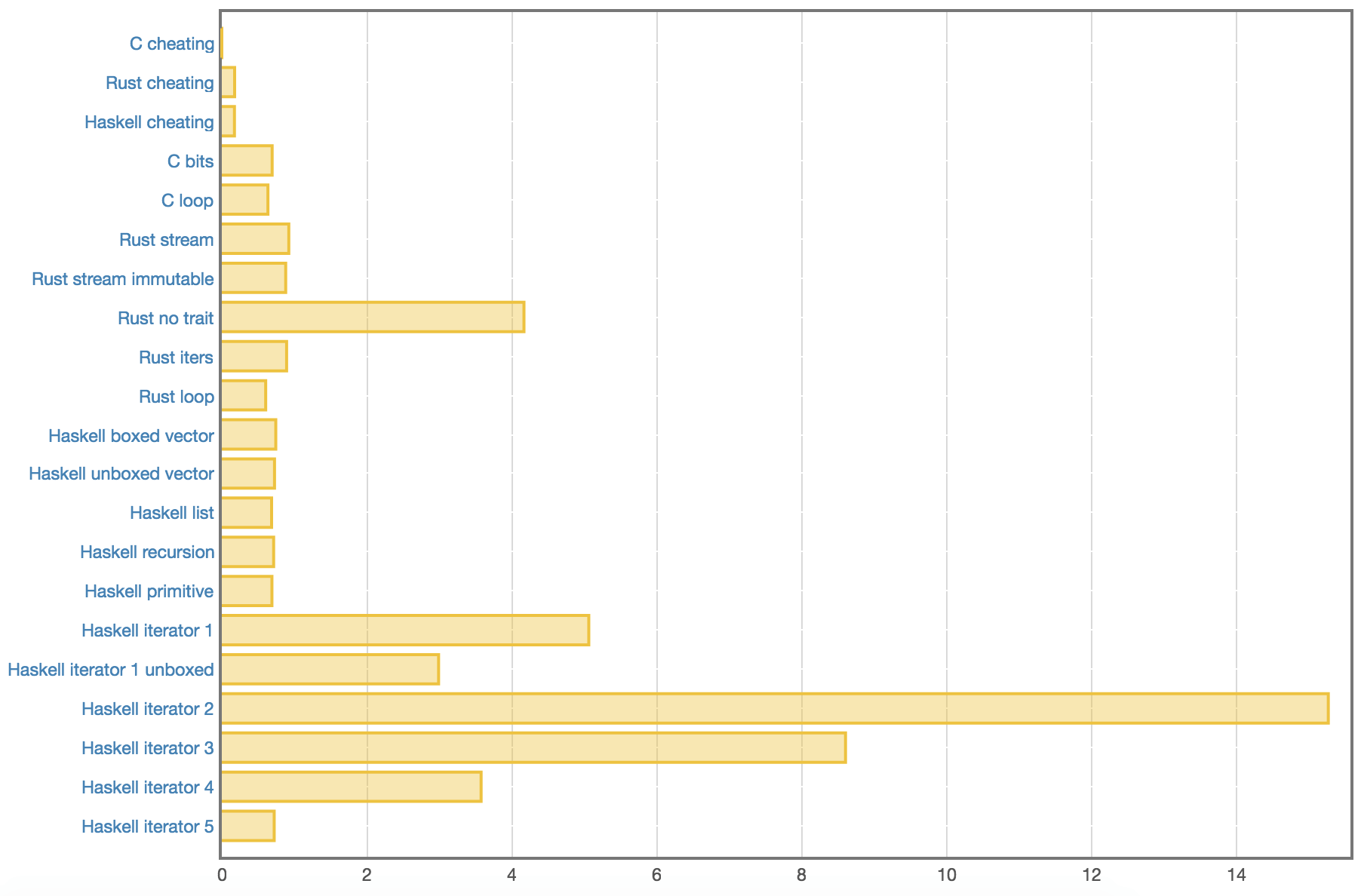
Also, each function takes an integer argument to tell it the
highest value it should count it (which is always 1,000,000).
Criterion requires this kind of argument be present to ensure that
the Haskell compiler (GHC) doesn't optimize away our function call
and give us bogus benchmarking results.
Baseline and cheating
The Gist includes code in Haskell, C, and Rust, with many
different implementations of the same kind of function. The Haskell
code foreign imports both Rust and C and uses the Criterion benchmarking
library to benchmark them. To start off, I implemented a
cheating version of each benchmark. Instead of actually filtering
and doubling, it just increments the counter by 4 each time and
adds it to a total. For example, in C this looks like:
int c_cheating(int high) {
int total = 0;
int i;
high *= 2;
for (i = 4; i <= high; i += 4) {
total += i;
}
return total;
}
By contrast, the non-cheating loop version in C is:
int c_loop(int high) {
int total = 0;
int i;
for (i = 1; i <= high; ++i) {
if (i % 2 == 0) {
total += i * 2;
}
}
return total;
}
Similarly, we have cheating and loop implementations in
Rust:
#[no_mangle]
pub extern fn rust_cheating(high: isize) -> isize {
let mut total = 0;
let mut i = 4;
let high = high * 2;
while i <= high {
total += i;
i += 4;
}
total
}
#[no_mangle]
pub extern fn rust_loop(mut high: isize) -> isize {
let mut total = 0;
while high > 0 {
if high % 2 == 0 {
total += high << 1;
}
high -= 1;
}
total
}
And in Haskell. Haskell uses recursion in place of looping, but
under the surface the compiler turns it into a loop at the assembly
level.
haskellCheating :: Int -> Int
haskellCheating high' =
loop 0 4
where
loop !total !i
| i <= high = loop (total + i) (i + 4)
| otherwise = total
high = high' * 2
recursion :: Int -> Int
recursion high =
loop 1 0
where
loop !i !total
| i > high = total
| even i = loop (i + 1) (total + i * 2)
| otherwise = loop (i + 1) total
These two sets of tests give us some baseline numbers to compare
everything else we're going to look at. First, the cheating
results:
benchmarking C cheating
time 87.13 ns (86.26 ns .. 87.99 ns)
0.999 R² (0.999 R² .. 1.000 R²)
mean 86.87 ns (86.08 ns .. 87.57 ns)
std dev 2.369 ns (1.909 ns .. 3.127 ns)
variance introduced by outliers: 41% (moderately inflated)
benchmarking Rust cheating
time 174.7 μs (172.8 μs .. 176.9 μs)
0.998 R² (0.997 R² .. 0.999 R²)
mean 175.2 μs (173.3 μs .. 177.3 μs)
std dev 6.869 μs (5.791 μs .. 8.762 μs)
variance introduced by outliers: 37% (moderately inflated)
benchmarking Haskell cheating
time 175.2 μs (172.2 μs .. 178.9 μs)
0.998 R² (0.995 R² .. 0.999 R²)
mean 174.6 μs (172.9 μs .. 176.8 μs)
std dev 6.427 μs (4.977 μs .. 9.365 μs)
variance introduced by outliers: 34% (moderately inflated)
You may be surprised that C is about twice as fast as Rust and
Haskell. But look again: C is taking 87 nanoseconds, while
Rust and Haskell both take about 175 microseconds. It turns
out that GCC it able to optimize this into a downward-counting
loop, which drastically improves the performance. We can do similar
things in Rust and Haskell to get down to nanosecond-level
performance, but that's not our goal today. I do have to say: well
done GCC.
The non-cheating results still favor C, but not to the same
extent:
benchmarking C loop
time 636.3 μs (631.8 μs .. 640.5 μs)
0.999 R² (0.998 R² .. 0.999 R²)
mean 636.3 μs (629.9 μs .. 642.9 μs)
std dev 22.67 μs (18.76 μs .. 27.87 μs)
variance introduced by outliers: 27% (moderately inflated)
benchmarking Rust loop
time 632.8 μs (623.8 μs .. 640.4 μs)
0.999 R² (0.998 R² .. 0.999 R²)
mean 626.9 μs (621.4 μs .. 631.9 μs)
std dev 18.45 μs (14.97 μs .. 23.18 μs)
variance introduced by outliers: 20% (moderately inflated)
benchmarking Haskell recursion
time 741.9 μs (733.1 μs .. 755.0 μs)
0.998 R² (0.996 R² .. 0.999 R²)
mean 748.7 μs (739.8 μs .. 762.8 μs)
std dev 36.37 μs (29.18 μs .. 52.40 μs)
variance introduced by outliers: 41% (moderately inflated)
EDIT Originally this article listed a
performance number for the C loop as being faster than Rust.
However,
as pointed out on Reddit, the code in question was mistakenly
using int instead of int64_t to match the
Rust and Haskell behavior. The numbers have been updated.
All of the results are the same order of magnitude. C and Rust
are neck and neck, with Haskell lagging by about 15%. Understanding
the differences between the languages' performance would be an
interesting topic in and of itself, but our goal today is to
compare the higher-level APIs and see how they affect performance
within each language. So for the rest of this post, we'll focus on
comparing intra-language performance numbers.
Rust's iterators
OK, with that out of the way, let's look at Rust's
implementation using iterators. The code is concise, readable, and
elegant:
#[no_mangle]
pub extern fn rust_iters(high: isize) -> isize {
(1..high + 1)
.filter(|x| x % 2 == 0)
.map(|x| x * 2)
.sum()
}
We can compare this pretty directly with a Haskell
implementation using lists or vectors:
list :: Int -> Int
list high =
sum $ map (* 2) $ filter even $ enumFromTo 1 high
unboxedVector :: Int -> Int
unboxedVector high =
VU.sum $ VU.map (* 2) $ VU.filter even $ VU.enumFromTo 1 high
This is the first interesting API difference between Haskell and
Rust. With Haskell, sum, map, and
filter are each functions which are applied to an
existing list or vector. You'll notice that, in the vector case, we
need to use a qualified import VU. to ensure we're
getting the correct version of the function. By contrast, in Rust,
we're simply calling methods on the Iterator trait.
This means that no namespacing is necessary, but on the other hand
adding a new iterator adapter would mean the new function would not
follow the same function call syntax as the others. (To me, this
seems like a watered down version of the expression problem.)
EDIT As
pointed out on Reddit, an extension trait can allow new methods
to be added to all iterators.
This doesn't seem like a big deal, but it does show an inherent
difference in how namespacing is handled in the two languages, and
the impact is fairly ubiquitous. I'd argue that this is a fairly
surface-level distinction, but an important one to note.
benchmarking Rust iters
time 919.5 μs (905.5 μs .. 936.0 μs)
0.998 R² (0.998 R² .. 0.999 R²)
mean 919.1 μs (910.4 μs .. 926.7 μs)
std dev 28.63 μs (24.52 μs .. 33.91 μs)
variance introduced by outliers: 21% (moderately inflated)
benchmarking Haskell unboxed vector
time 733.3 μs (722.6 μs .. 745.2 μs)
0.998 R² (0.996 R² .. 0.999 R²)
mean 742.4 μs (732.2 μs .. 752.8 μs)
std dev 33.42 μs (28.01 μs .. 41.24 μs)
variance introduced by outliers: 36% (moderately inflated)
benchmarking Haskell list
time 714.0 μs (707.0 μs .. 720.8 μs)
0.999 R² (0.998 R² .. 0.999 R²)
mean 710.4 μs (702.7 μs .. 719.4 μs)
std dev 26.49 μs (21.79 μs .. 33.72 μs)
variance introduced by outliers: 29% (moderately inflated)
Interesting. While the Haskell benchmarks are about the same as
the lower-level recursion approach, the Rust iterator
implementation is noticeably slower than the low level loop. I have
my own theory on what's going on there, and I'll share it below.
Unfortunately, my Rust skills are not strong enough to properly
test my hypothesis.
Implementing iterators
in Haskell
In Rust, there is an Iterator trait with an
associated type Item and a method next.
Eliding some extra methods we don't care about here, it looks like
this:
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}
Let's translate this directly to Haskell:
class Iterator iter where
type Item iter
next :: iter -> Maybe (Item iter)
That looks remarkably similar. Some basic differences worth
noting:
- In Rust, we use
pub to indicate if something is
publicly exposed. In Haskell, we use export lists on the
module.
- Instead of
Self, Haskell uses type variables (I
called it iter here)
- Function signature syntax is different
- Rust tracks information about mutability and references. This
is a big difference, and will play out a lot in this post,
so I won't detail it too much here
- Rust says
Option, Haskell says
Maybe
Let's do a simple implementation in Rust:
struct PowerUp {
curr: u32,
}
impl Iterator for PowerUp {
type Item = u32;
fn next(&mut self) -> Option<u32> {
if self.curr > 9000 {
None
} else {
let res = self.curr;
self.curr += 1;
Some(res)
}
}
}
This will iterate through all of the numbers between the
starting value and 9000. But there's one line in particular I want
to draw your attention to:
self.curr += 1;
That is mutation, and for anyone familiar with Haskell,
you know we don't like it very much. In fact, our
Iterator typeclass above doesn't work at all, since it
has no way of mutating a variable. In order to make this work,
we'll need to modify our class. Since we'll have lots of these, I'm
going to start numbering them:
class Iterator1 iter where
type Item1 iter
next1 :: iter -> IO (Maybe (Item1 iter))
The point is that, each time we iterate our value, it can have
some side-effect of mutating a variable. This is a crucial
distinction between Rust and Haskell. Rust tracks whether
individual values can be mutated or not. And it even defaults to
(IMO) the right behavior of immutability. Nonetheless, there is no
indication in the type signature of a function that it performs
side effects.
Let's power up in Haskell:
data PowerUp = PowerUp (IORef Int)
instance Iterator1 PowerUp where
type Item1 PowerUp = Int
next1 (PowerUp ref) = do
curr <- readIORef ref
if curr > 9000
then return Nothing
else do
writeIORef ref $! curr + 1
return $ Just curr
Ignoring unimportant syntax differences:
- In Haskell, we explicitly need to wrap any mutable field with
an
IORef (or similar mutable variable)
- Similarly, we need to use explicit
readIORef and
writeIORef functions to access the value, as opposed
to getting and modifying values directly in Rust.
- You may have noticed the
$! before curr +
1. If you were paying close attention above, in the
recursion function, I had something similar with
loop !i !total. These are special operators and syntax
in Haskell to force evaluation. This is because Haskell is lazy
by default, whereas Rust is strict by default.
Alright, so I went ahead and implemented everything with this
Iterator1 class and ended up with:
iterator1 :: Int -> Int
iterator1 high =
unsafePerformIO $
enumFromTo1 1 high >>=
filter1 even >>=
map1 (* 2) >>=
sum1
We're using unsafePerformIO here, since we want to
run this function purely, but it's performing side-effects. A
better approach in Haskell is using the ST type, but
I'm going for simplicity here. I'm not going to copy the
implementation of the types here; please take a look at the Gist if
you're curious.
Now let's look at performance:
benchmarking Haskell iterator 1
time 5.181 ms (5.108 ms .. 5.241 ms)
0.997 R² (0.993 R² .. 0.999 R²)
mean 5.192 ms (5.140 ms .. 5.267 ms)
std dev 179.5 μs (125.3 μs .. 294.5 μs)
variance introduced by outliers: 16% (moderately inflated)
That's 5 milliseconds, or 5000 microseconds. Meaning, a
hell of a lot slower than recursion, lists, and vectors. So we've
hit three hurdles:
- The code looks less clean that the list/vector version
- We've had to pull out
unsafePerformIO
- And performance sucks
I guess idiomatic Rust isn't so idiomatic in Haskell.
Boxed vs unboxed
Haskell aficiandos may have noticed one major performance
bottleneck in what I've presented. IORefs are
boxed data structures. Meaning: the data they contain is
actually a pointer to a heap object. This means that, each time we
write a new Int to an IORef, we have
to:
- Allocate a new heap object to hold it. That heap object needs
to be big enough to hold the payload (one machine word) and the
data constructor (another machine word).
- Update the pointer inside the
IORef to the new
heap object.
- Garbage collect the old heap object. This won't happen
immediately, but is an overhead incurred for each iteration.
Fortunately, there's a workaround for this: unboxed references.
There's a library
providing them, and switching over to them in our
implementation drops the runtime to:
benchmarking Haskell iterator 1 unboxed
time 2.966 ms (2.938 ms .. 2.995 ms)
0.999 R² (0.999 R² .. 1.000 R²)
mean 2.974 ms (2.952 ms .. 3.007 ms)
std dev 84.05 μs (57.67 μs .. 145.2 μs)
variance introduced by outliers: 13% (moderately inflated)
Better, but still not great. The simple fact is that Haskell is
not optimized for dealing with mutable data. There are some use
cases that still work well for mutable data in Haskell, but this
kind of low level, tight inner loop isn't one of them.
As a side note: as much as I'm implying that boxed references
are a terrible thing in Haskell, they have some great advantages.
The biggest is atomic operations: an operation like
atomicModifyIORef or the entirety of Software
Transactional Memory (STM) leverage the fact that they can create a
new multi-machine-word data structure on the heap, and then
atomically update the one-machine-word pointer. That's pretty
nifty.
Immutable
Alright, the mutable variable approach seems like a dead end.
Let's get more idiomatic with Haskell: immutable values. We'll take
in an iterator state, and return an updated state:
data Step2 iter
= Done2
| Yield2 !iter !(Item2 iter)
class Iterator2 iter where
type Item2 iter
next2 :: iter -> Step2 iter
We've added a helper data type to capture what's going on here.
At each iteration, we can either be done, or yield both a new value
and a new state for our iterator. The IO bit has
disappeared, since there are no mutation side-effects occuring.
This implementation turned out to be wonderfully inefficient:
benchmarking Haskell iterator 2
time 15.80 ms (15.06 ms .. 16.64 ms)
0.992 R² (0.987 R² .. 0.998 R²)
mean 15.16 ms (14.99 ms .. 15.41 ms)
std dev 561.5 μs (363.6 μs .. 934.6 μs)
variance introduced by outliers: 11% (moderately inflated)
Why the hate? It turns out that we've just exacerbated our
previous problem. Before, each iteration caused a new
Int heap object to be created and a pointer to be
updated. Now, each iteration causes a bunch of new heap
objects, namely all of our data types representing the various
functions:
data EnumFromTo2 a = EnumFromTo2 !a !a
data Filter2 a iter = Filter2 !(a -> Bool) !iter
data Map2 a b iter = Map2 !(a -> b) !iter
These are built up and torn down each time we iterate, which is
pretty pathetic performance wise. If Haskell could inline the
embedded iter fields in each of these data
constructors (via the UNPACK pragma), life would be
better, but GHC can't unpack polymorphic fields. So we're creating
3 new heap objects each time.
I've included Iterator3 in the Gist, which
monomorphizes things a whole bunch to allow inlining. As expected,
it improves performance significantly:
benchmarking Haskell iterator 3
time 8.391 ms (8.161 ms .. 8.638 ms)
0.996 R² (0.994 R² .. 0.999 R²)
mean 8.397 ms (8.301 ms .. 8.517 ms)
std dev 300.0 μs (218.4 μs .. 443.9 μs)
variance introduced by outliers: 14% (moderately inflated)
But it's still bad. Something more fundamental is wrong
here.
Functions are data
Until now in Haskell, we've stuck with the Rust approach of:
- Declare a trait (type class)
- Define a data type for each operation
- Implement the trait/instanciate the class for each data
type
This seems to work really well for Rust (more on that below).
But it's neither idiomatic Haskell code, nor does it play nicely
with Haskell's runtime behavior and garbage collector. Let's
remember that, in Haskell, functions are data, and completely
bypass the typeclass:
data Step4 s a
= Done4
| Yield4 s a
data Iterator4 a = forall s. Iterator4 s (s -> Step4 s a)
Our Step4 data type has two type variables:
s is the internal state of the iterator, and
a is the next value to be yielded. Now the cool part:
Iterator4 says "well, the outside world cares about
the a type variable, but the internal state is
irrelevant." So it uses an existential to say "this works for all
possible internal states."
We then have two fields: the current value of the state, and a
function that gets the next step from the current state. To really
drive this home, we'll need to look at some implementations:
enumFromTo4 :: (Ord a, Num a) => a -> a -> Iterator4 a
enumFromTo4 start high =
Iterator4 start f
where
f i
| i > high = Done4
| otherwise = Yield4 (i + 1) i
We've define a helper function f. This
f function remains constant throughout the entire
lifetime of enumFromTo4. Only the i value
it is passed gets updated. And let's see how we would call one of
these Iterator4s:
sum4 :: Num a => Iterator4 a -> a
sum4 (Iterator4 s0 next) =
loop 0 s0
where
loop !total !s1 =
case next s1 of
Done4 -> total
Yield4 s2 x -> loop (total + x) s2
We capture the next function once and then use it
throughout the loop. This may not seem too different from previous
code: we're still going to need to create a new state value and
destroy it each time we iterate. However, that's not the case: GHC
is smart enough to realize that our state is just a single machine
Int, and ends up storing it in a machine register,
bypassing heap allocations entirely.
Don't get too excited yet though. While we've decimated iterator
2 and 3, our performance is still bad:
benchmarking Haskell iterator 4
time 3.614 ms (3.559 ms .. 3.669 ms)
0.998 R² (0.997 R² .. 0.999 R²)
mean 3.590 ms (3.542 ms .. 3.641 ms)
std dev 151.4 μs (116.4 μs .. 192.4 μs)
variance introduced by outliers: 24% (moderately inflated)
We've got one more trick up our performance sleeve, after a
message from our sponsors.
Why Rust likes data types
We've seen that the Rust implementation uses individual data
types for each operation. But surely with its first class
functions, it should be able to do the same thing as Haskell,
right? I'm not a Rust expert, but I believe the answer is: yes, but
the performance will suffer greatly.
To explain why, consider the type of the expression
(1..high + 1).filter(|x| x % 2 == 0).map(|x| x *
2):
std::iter::Map<
std::iter::Filter<
std::ops::Range<isize>,
[[email protected]:7:17: 7:31]
>,
[[email protected]:8:14: 8:23]
>
As a Haskeller, when I first realized that this type was being
employed, I was pretty confused. By contrast, the type of the the
equivalent Haskell expression map4 (* 2) $ filter4 even $
enumFromTo4 1 high is just Iterator Int, which
seems much more direct.
Here's the rub: Haskell is happy—perhaps even too happy—to just
stick data on the heap and forget about it. We don't care about the
size of our data as much, since we'll just stick a pointer into a
data structure. Rust, by contrast, does really well when data is
stored on the stack. In order to make that happen, it needs to know
the exact size of the data in question. And therefore, instead of
the Filter data structure getting to say "yeah, I just
work on any data structure that implements Iterator,"
it is generic over all possible implementations.
This is similar to the lack of polymorphic unpacking in Haskell
that I mentioned aboved, and leads to inherently different coding
styles in many cases, including this one. Also, this behavior of
Rust is in direct contradiction to the existential we used above to
explicitly hide internal state from our type signature, whereas in
Rust we're flaunting it.
A single loop
Alright, back to our pessimal performance problems. We could do
a bunch of performance analyses right now, look at GHC generated
core and assembly, and spend months writing up a paper on how to
improve performance. Fortunately, someone else already
did it. To understand the problem, let's look at our
Iterator4 again. We already saw that there's a loop in
the implementation of sum4, as you'd expect. Let's see
filter4:
filter4 :: (a -> Bool) -> Iterator4 a -> Iterator4 a
filter4 predicate (Iterator4 s0 next) =
Iterator4 s0 loop
where
loop s1 =
case next s1 of
Done4 -> Done4
Yield4 s2 x
| predicate x -> Yield4 s2 x
| otherwise -> loop s2
Notice the loop here as well: if the predicate fails, we need to
drop a value, and therefore need to call next again.
It turns out that GHC is really good at optimizing code that has a
single loop, but performance degrades terribly when you have two
nested loops, like we do here.
The stream fusion paper provides the solution to this problem:
extend our Step datatype with a Skip
constructor, which indicates "loop again with a new state, but I
don't have any new data available."
data Step5 s a
= Done5
| Skip5 s
| Yield5 s a
Then our implementations change a bit. filter5
becomes:
filter5 :: (a -> Bool) -> Iterator5 a -> Iterator5 a
filter5 predicate (Iterator5 s0 next) =
Iterator5 s0 noloop
where
noloop s1 =
case next s1 of
Done5 -> Done5
Skip5 s2 -> Skip5 s2
Yield5 s2 x
| predicate x -> Yield5 s2 x
| otherwise -> Skip5 s2
Notice the total lack of a loop. If the predicate fails, we
simply Skip5. The implementation of sum5
has to change as well:
sum5 :: Num a => Iterator5 a -> a
sum5 (Iterator5 s0 next) =
loop 0 s0
where
loop !total !s1 =
case next s1 of
Done5 -> total
Skip5 s2 -> loop total s2
Yield5 s2 x -> loop (total + x) s2
Cue the drumroll... and our performance is now:
benchmarking Haskell iterator 5
time 744.5 μs (732.1 μs .. 761.7 μs)
0.996 R² (0.994 R² .. 0.998 R²)
mean 768.6 μs (757.9 μs .. 780.8 μs)
std dev 38.18 μs (31.22 μs .. 48.98 μs)
variance introduced by outliers: 41% (moderately inflated)
Whew, we've gone all the way back to recursion-level
performance. An astute reader may be wondering why we bothered at
all, when lists and vectors got similar performance. A few
things:
- Vectors use this stream fusion technique under the surface
- Lists use a different fusion framework (build/foldr) which has
different tradeoffs than stream fusion, and therefore handles some
other cases much worse
- We can extend this
Iterator5 approach to include
IO and perform side effects (like reading from a file)
between actions, which can't be done with lists
We've ended up with idiomatic Haskell code, involving no
unnecessary data types or type classes, leveraging first-class
functions, and dealing in immutable data. We've added an
optimization specifically tailored for GHC's preferred code
structure. And we get relatively simple high level code with great
performance.
And finally, along the way, we got to see some places where Rust
and Haskell take very different approaches to the same problem. My
personal takeaway is that it's pretty astounding that, with its
heap-friendly, garbage collected nature, the performance of the
Haskell code is competitive with Rust's.
Why are Rust
iterators slower than looping?
If you remember, there was a substantial slowdown when going
from Rust loops to Rust iterators. This was a bit disappointing to
me. I'd like to understand why. Unfortunately, I don't have
an answer right now, only a hunch. And that hunch is that the
double-inner-loop problem is kicking in. This is just conjecture
right now.
I tried implementing a "stream fusion" style implementation in
Rust that looks like this:
enum Step<T> {
Done,
Skip,
Yield(T),
}
trait Stream {
type Item;
fn next(&mut self) -> Step<Self::Item>;
}
Almost identical to Iterator, except it uses
Step instead of Option, allowing the
possibility of Skipping. Unfortunately I saw a
slowdown there:
benchmarking Rust stream
time 958.7 μs (931.2 μs .. 1.007 ms)
0.968 R² (0.925 R² .. 0.999 R²)
mean 968.0 μs (944.3 μs .. 1.019 ms)
std dev 124.1 μs (45.79 μs .. 212.7 μs)
variance introduced by outliers: 82% (severely inflated)
This could be for many reasons, including better optimizations
for Option versus my Step enum, or simply
my inability to write performant Rust code. (Or that my theory is
just dead wrong, and skip only gets in the way.)
Then I decided to try a similar approach, using immutable state
values instead of mutable ones, which looked like:
enum StepI<S, T> {
Done,
Skip(S),
Yield(S, T),
}
trait StreamI where Self: Sized {
type Item;
fn next(self) -> StepI<Self, Self::Item>;
}
This implementation was a bit faster than the mutable one, most
likely due to user error on my part:
benchmarking Rust stream immutable
time 878.4 μs (866.9 μs .. 888.9 μs)
0.998 R² (0.997 R² .. 0.999 R²)
mean 889.1 μs (878.7 μs .. 906.0 μs)
std dev 44.75 μs (27.17 μs .. 86.29 μs)
variance introduced by outliers: 41% (moderately inflated)
A big takeaway from me here was the impact of move semantics in
Rust. The ability to fully "consume" an input value and prevent it
from being used again is the kind of thing I often want to state in
Haskell, but am unable to. On the other hand: dealing with moved
values feels tricky in Rust, but that's likely just lack of
experience speaking.
The final implementation I tried out in Rust was explicitly
passing closures around like we do in Haskell (though including
mutable variables). I'm not sure I chose the best representation,
but ended up with:
struct NoTrait<A> {
next: Box<(FnMut() -> Option<A>)>,
}
As an example, the range function looked like
this:
fn range_nt(mut low: isize, high: isize) -> NoTrait<isize> {
NoTrait {
next: Box::new(move || {
if low >= high {
None
} else {
let res = low;
low += 1;
Some(res)
}
})
}
}
This is pretty close in spirit to how we do things in Haskell,
and could be modified to be completely non-mutating if desired with
explicit state passing. Anyway, the performance turned out to be
(as I'd expected) pretty bad:
benchmarking Rust no trait
time 4.206 ms (4.148 ms .. 4.265 ms)
0.998 R² (0.998 R² .. 0.999 R²)
mean 4.197 ms (4.155 ms .. 4.237 ms)
std dev 134.4 μs (109.6 μs .. 166.0 μs)
variance introduced by outliers: 15% (moderately inflated)
GHC is optimized for these kinds of cases, since passing around
closures and partially applied functions is standard practice in
Haskell. In our Iterator5 implementation, GHC will end
up inlining all of the intermediate functions, and then see through
all of the closure magic to turn our code into a tight inner loop.
This is non-idiomatic Rust, and therefore (AFAICT) the compiler is
not performing any such optimizations.
Consider the fact that it has to perform explicit function calls
at each step of the iteration, I'd say that the fact that the Rust
implementation is only an order of magnitude slower than iterators
is pretty impressive.
Conclusion
I find the contrasts between these two languages to be very
informative. I definitely walked away with a better understanding
of Rust after performing this analysis. And at a higher level, I
think the Haskell ecosystem can learn from Rust's focus on
zero-cost abstractions in our library design a bit more.
I'd love to hear from Rustaceans about why the iterator version
of the code is slower than the loop. I'd be especially interested
if some of the ideas from stream fusion could be used to help that
speed difference disappear.
And finally: GCC deserves a shoutout for optimizing the hell out
of its code and confusing me with crazy assembly until Chris Done
helped me work through it :).
Subscribe to our blog via email
Email subscriptions come from our Atom feed and are handled by Blogtrottr. You will only receive notifications of blog posts, and can unsubscribe any time.
Do you like this blog post and need help with Next Generation Software Engineering, Platform Engineering or Blockchain & Smart Contracts? Contact us.